
С Дмитрием Браженко (Microsoft) построили RAG с нуля и улучшили его с помощью механик и эвристик.
Как оценивать качество поиска? Как перейти от варианта «на коленке» к продакшну? — вместе найдем ответы на эти наболевшие вопросы.
Хочешь настроить модель на своём корпусе? Читай статью до конца, скачивай код и общайся с моделью на основе своих материалов!
YNDX Family
Материал подготовлен на основе онлайн-встречи YNDX Family, неофициального сообщества текущих и бывших сотрудников Яндекса. Присоединяйся к комьюнити, если ты тоже выпускник-яндексоид :) А полную запись встречи можно посмотреть по ссылке на YouTube канале.
Как заставить твои данные заговорить с тобой без шизофрении и галлюцинаций?
Сегодня мы построим RAG-систему, которая сможет разговаривать с тобой на основе какого-либо локального знания, например, списка источников твоей курсовой.
В качестве LLM у нас сегодня – модель от Open AI. Но можно использовать и другие.
Этап 1. Эмбеддинги и для чего они нужны
Предположим, у нас есть набор данных, например, несколько абзацев текста. Мы хотим найти в них информацию, релевантную нашему запросу. Можем запустить поиск по ключевым словам. Но тогда мы ограничим себя в функционале: например, машина не сможет найти синонимы.
Есть альтернатива – векторный поиск с помощью эмбеддингов.
🤖Как это работает: Мы выражаем наш текст через вектор. Последние не несут особого смысла, но имеют несколько важных характеристик. Например, векторы двух схожих по семантике высказываний будут ближе, чем те, значениях которых никак не связаны.
Давайте разберём работу эмбеддингов на примере корпуса из нескольких предложений.
Let's try [`all-MiniLM-L6-v2`](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) modelmodel = SentenceTransformer('all-MiniLM-L6-v2')
sentences = [
'Python is a cool programming language',
'Python is an amazing programming language. There a lot of apps that are made using python',
'London is a big city',
'London has 9,787,426 inhabitants at the 2011 census',
'London is known for its finacial district',
'I am cooking python for breakfast right now',
'I am cooking a lunch right now',
'I am NOT cooking any meal right now'
]
embeddings = model.encode(sentences)
print(embeddings[0][: 20])
print(len(embeddings[0]))
[-0.06981423 -0.0010024 0.0076027 0.00425244 -0.04276219 -0.16027543
0.01579451 0.04823529 -0.01330455 0.01159351 -0.00749934 0.02610185
0.08388049 0.0311769 0.03688725 -0.02012014 -0.06381261 0.0093547
-0.00549993 -0.1540702 ]
384Вектор каждого предложения имеет 384 числовых значения (самое нижнее число).
На основе этих данных строим матрицу похожести по парам для каждого из предложений.
sns.heatmap(cosine_similarity(embeddings), annot=True, cmap='coolwarm', xticklabels=False, yticklabels=False)
<Axes: >
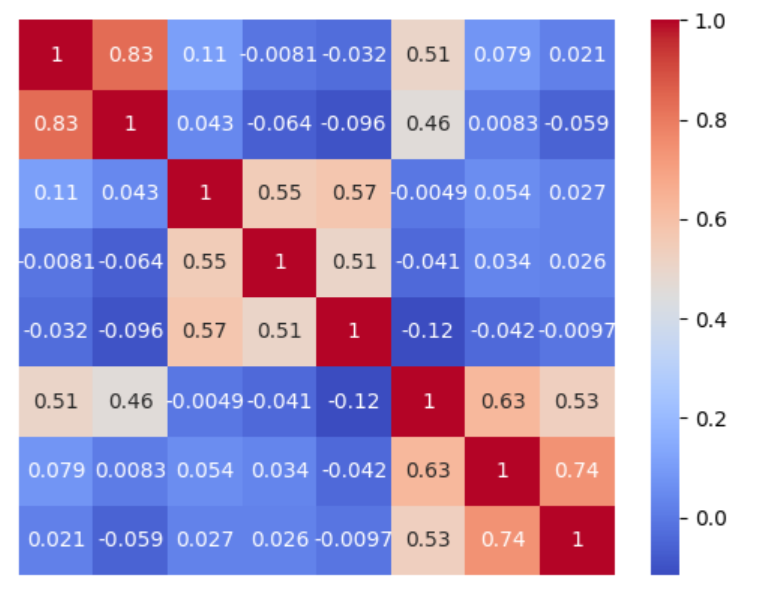
Что мы видим?
Во-первых, значения соседних квадратов в левом верхнем углу показывают, что предложения 1 и 2 из предыдущего скриншота связаны сильнее (0,83), чем первое и третье (0,11).
Во-вторых, предложения «Python is a cool programming language» и «I’m cooking python for breakfast right now» (интересно пообщаться с таким персонажем😀), хоть и содержат схожие элементы, но модель понимает: речь идёт о совершенно разных ситуациях.
Таким образом, мы доказали: механизм эффективен.
Эмбеддинговых моделей очень много. Некоторые натренированы на программистских запросах, другие – хорошо работают с Q&A. Рассмотрим последний тип подробнее.
Модель ниже анализирует, какое из трёх предложений наиболее релевантно запросу: «What is the US capital?»
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("multi-qa-MiniLM-L6-cos-v1")
query_embedding = model.encode("What is the US capital?")
passage_embedding = model.encode([
"London has 9787426 inhabitants at the 2011 census",
"London is known for its finacial district",
"Washington, DC is the U.S. capital"
])
print("Similarity:", util.dot_score(query_embedding, passage_embedding))
Similarity: tensor([[0.0115, 0.1315, 0.6870]])Индекс similarity говорит, что последнее высказывание ближе всего по смыслу. Попробуем изменить запрос. Видим, что модель тоже неплохо справляется 🙂
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("multi-qa-MiniLM-L6-cos-v1")
query_embedding = model.encode("What is the population of the capital of the UK?")
passage_embedding = model.encode([
"London has 9787426 inhabitants at the 2011 census",
"London is known for its finacial district",
"Washington, DC is the U.S. capital"
])
print("Similarity:", util.dot_score(query_embedding, passage_embedding))
Similarity: tensor([[0.6134, 0.4554, 0.2468]])Embedding models references:
* https://www.sbert.net/docs/pretrained_models.html
* https://platform.openai.com/docs/guides/embeddingsТаким образом, если ты правильно подберешь эмбеддинговую модель, у тебя появится сильный инструмент для поиска семантических сходств.
Этап 2. Базы данные векторов (Vector DB)
Чтобы хранить наши векторы, нужна база данных, например, lancedb. Она наиболее удобна при локальном использовании. Для более тяжёлых систем существуют специфические решения – универсального ответа здесь нет.
Но пока остановимся на lancedb и сохраняем все эмбеддинги в базу данных.
data = []
for sentence in sentences:
data.append({"vector": model.encode(sentence),
"sentence": sentence})
uri = "data/sample-lancedb"
db = lancedb.connect(uri)
table = db.create_table("my_table",
data=data)Попробуем извлечь похожие предложения по запросу cooking.
result = table.search(model.encode("Cooking")).metric("cosine").limit(3).to_pandas()
result
Как видим, модель справилась неплохо. Теперь зададим промпт python programming. Видим, что в нижнем запросе программа не справилась с многозначностью нашего питона 🐍
result = table.search(model.encode("Python programming")).metric("cosine").limit(3).to_pandas()
result
Чтобы улучшить результат, нам нужен другой подход.
Этап 3. Cross Encoder как альтернатива эмбеддингам
Напомню: до этого мы с тобой ранжировали несколько вариантов по степени схожести. Но можно поступить по-другому. Используя Cross Encoder, зададим вопрос, похожи ли соотносимые предложения. Пересчитаем значения для наших предложений.
from sentence_transformers import CrossEncoder
model = CrossEncoder('cross-encoder/ms-marco-TinyBERT-L-2-v2', max_length=512)
scores = model.predict([
("Python programming", result['sentence'].iloc[0]),
("Python programming", result['sentence'].iloc[1]),
("Python programming", result['sentence'].iloc[2])
])
scores
array([10.1110935, 9.059612 , -5.421424 ], dtype=float32)Видим, что первые 2 предложения ожидаемо больше связаны с программированием, чем последняя. Теперь модель нас понимает.
😬 Минус: чем больше предложений мы получаем на входе, тем тяжелее и дольше идёт процесс.
Два подхода легко комбинировать: с помощью эмбеддингов ты можешь извлечь предварительный набор предложений, а дальше, с помощью Cross Encoder, определить лучшие варианты в зависимости от результата (score).
Этап 4. Нешуточная борьба со здравым смыслом
Итак, мы создали движок для поиска документов. Давай представим, что ты пользователь, который задаёт запрос в чат. Машина понимает, что нужно взять информацию из базы знаний, а после этого вернуться с ответом, уточнением или выполненным действием (распечатать что-то, отправить письмо на почту и т.д.).
Иногда чат начинает галлюцинировать – доставать знания не из твоих данных, а из обучающего датасета или, что ещё хуже, изобретает это знание самостоятельно.
Как бороться с этим?
Интересный способ валидации – работа с фейками 🙂
Вот их примеры:
fake_facts = [
"Penguins can fly if they eat enough fish.",
"Tomatoes are classified as both a fruit and a vegetable due to a genetic anomaly.",
"The Sahara Desert was once a thriving rainforest before climate change.",
"Sharks are afraid of the color yellow and avoid it at all costs.",
"Cats can see in complete darkness because they have infrared vision.",
"The Internet is powered by thousands of hamsters running on wheels.",
"The pyramids of Egypt were built by a civilization of intelligent ants.",
"Mars was once home to an advanced alien civilization that built canals.",
"Rainbows are actually circular, but we only see half of them from the ground.",
"A person can survive for a month by only drinking coffee and eating chocolate.",
"Alligators have been known to climb trees to hunt for prey.",
"The Earth's core is made entirely of cheese, which is why we have so many dairy products.",
"Owls can turn their heads in a full 360-degree circle.",
"Dolphins communicate with each other using a complex language of clicks and whistles that humans can learn.",
"Jellyfish are immortal and can live forever unless they are eaten.",
"Bananas grow upside down in Australia due to gravitational differences.",
"The Eiffel Tower can shrink by up to six feet during extremely cold weather.",
"Elephants can jump higher than kangaroos when motivated by food.",
"The Great Wall of China was originally built to keep out giant mutant pandas.",
"Lightning never strikes the same place twice because the earth’s rotation prevents it.",
"Cows produce chocolate milk if they are fed chocolate.",
"Mount Everest is actually growing at a rate of five feet per year.",
"Bees can understand human language but choose not to respond.",
"The moon is slowly drifting towards Earth and will collide in 500 million years.",
"Humans have a natural instinct to spin in circles when they see a rainbow."
]Давай поставим эксперимент. Загрузив наш набор «знаний» в базу данных, вводим запроc на основе первого предложения: «Пингвины могут полететь, если съедят достаточно рыбы». Добавляем требование ясности и чёткости формулировки и получаем ответ (в самом низу):
PROMPT = f"""
USING PROVIDED DATA BELOW YOU **MUST** ANSWER USER'S QUESTION.
**PROVIDED INFORMATION**:
{formatted}
**USER'S QUESTION**:
{question}
**ANSWER MUST BE CLEAR AND PROMPT AND **MUST** BE BASED ON PROVIDED INFORMATION ONLY **
"""response = openai_client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": PROMPT
}
]
}
],
temperature=0,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
print(response.choices[0].message.content)
Yes, penguins can fly if they eat enough fish.Наша модель ориентировалась именно на загруженные в неё знания – галлюцинаций нет. Значит, мы хорошо настроили модель и написали промпт.
Если бы модель ответила верно с точки зрения здравого смысла, значит, она бы опиралась на данные из других источников. Это не то, что мы просим.
В случае ошибки следует усовершенствовать промпт. Лучше добавить фильтры или разработать для этих целей специальную метрику, чтобы ускорить работу. Но универсального способа улучшения нет.
Теперь ты можешь построить LLM, которая будет выполнять эту последовательность действий и сама оценивать, насколько верно дан ответ. Затем считаем score и делаем вывод, работает ли модель.
Этап 5. Работа с большими данными: усложняем пайплайн
Следует понимать, что реальные данные устроены гораздо сложнее, чем те, с которыми мы работали выше. Чаще всего модель работает с многостраничными файлами с картинками и таблицами.
Есть несколько подходов, которые позволят тебе выйти на новый уровень.
Рассмотрим один из них.
- Мы разбиваем текст на блоки и для каждого из них создаём эмбеддинги.
- Загружаем их в базу данных и ищем схожие по смыслу кусочки.
😬 Минус: Цельная мысль может быть разрезана и помещена в разные блоки (кусочки предложений или абзацы, связанные семантически).
Как избежать этого:
- После деления на блоки лучше скармливать их не по одному, а вместе с предыдущим и последующим, чтобы модель не теряла взаимосвязи. Конечно, база знаний будет в 3 раза тяжелее, зато ответ – точнее.
- Разделить текст так, чтобы блок был равен главе. Перед каждой из них поместить summary и работать по эмбеддингам этих данных.
А теперь – к практике 💪
В качестве сложного файла возьмём pdf-ку про нутрициологию. Разрежем её на блоки, посчитаем эмбеддинги и сохраним в базу знаний. В результате мы получим таблицу с данными.
## Let's index a file
```Ingest text -> split it into groups/chunks -> embed the groups/chunks -> use the embeddings```
source: https://github.com/mrdbourke/simple-local-rag/blob/main/00-simple-local-rag.ipynb
1. Easiest way: split by chunks
2. More advanced approaches: paragraphs/pages/...pages = convert_pdf_to_text("Human-Nutrition-2020.pdf")
chunks = split_pages_into_chunks(pages, 256, tiktoken.encoding_for_model('gpt-3.5-turbo'))data = []
for sentence in tqdm(chunks):
data.append({"vector": model.encode(sentence),
"sentence": sentence})
uri = "data/sample-lanced3"
db = lancedb.connect(uri)
table_nutricion = db.create_table("my_table",
data=data)
100%|██████████| 1871/1871 [04:52<00:00, 6.40it/s]- Задаём вопрос: «Вреден ли алкоголь для здоровья?»
- Извлекаем знания, схожие с запросом (после слова result).
- Получаем куски текста, которые сформулированы криво, но хотя бы релевантны нашим требованиям.
question = "is alcohol bad for health"
result = table_nutricion.search(model.encode(question)).metric("cosine").limit(3).to_pandas()
formatted = "".join([f"*{line}\n" for line in result['sentence']])
print(formatted)*annutrition2 /?p=283
Alcohol M etabolism | 441Health Conse quenc es of
Alcohol Abuse
UNIVER SITY OF HA WAI‘I A T MĀNOA FOOD SCIENCE AND HUMAN
NUTRITION PR OGRAM AND HUMAN NUTRITION PR OGRAM
Alcoholic drinks in e xcess c ontribute to w eight gain b y substan tially
increasing c aloric in take. H owever, alc ohol displa ys its two-fac ed
char acter again in i ts effects on bod y weight, making man y scien tific
studies c ontradictory. Multiple studies sho w hig h intakes o f har d
liquor ar e link ed to w eight gain, althoug h this ma y be the r esult
of the r egular c onsumption o f har d liquor wi th sugar y soft drinks,
juices, and other mix ers. On the other hand drinking be er and, e ven
more so, r ed wine, is not c onsisten tly link ed to w eight gain and
in some studies ac tuall y
* been
excluded fr om this ver sion of the te xt. You can
view it online her e:
http:/ /pressbooks. oer.hawaii. edu/
humannutrition2 /?p=27 4
Proteins, Die t, and P ersonal Choic es | 427PART VII
CHAPTER 7 . ALCOHOL
Chapter 7 . Alcohol | 429Image by
Allison
Calabr ese /
CC B Y 4.0 Introduction
UNIVER SITY OF HA WAI‘I A T MĀNOA FOOD SCIENCE AND HUMAN
NUTRITION PR OGRAM AND HUMAN NUTRITION PR OGRAM
Ka wai h oʻomalule kin o
The liquid that causes limpness to the body
Learnin g Objectives
By the end o f this chapter , you will be able to:
Introduc tion | 431• Describe the pr ocess o f alcohol me tabolism
• Describe the he alth benef its and he alth risks
associa ted with alc ohol c onsumption
Alcohol is both a be verage pr
* he art dise ase and Type 2 diabe tes in some
people. The Uni ted States Depar tmen t of Health and H uman
Services (HHS) def ines drinking in moder ation as no mor e than one
drink a da y for w omen and t wo drinks a da y for men5.
Illicit and pr escription drug abuse ar e associa ted wi th de creased
health and is a pr ominen t problem in the Uni ted States. The he alth
3. Centers f or Dise ase Con trol and Pr evention (20 20, April
28). Tobacco and M ortality . http://www.cdc.go v/
tobac co/data_sta tistics /fac t_she ets/health_ef fects/
tobac co_related_mor tality/Index.htm.
4. Centers f or Dise ase Con trol and Pr evention (20 20,
Januar y 3). Under age Drinking. http://www.cdc.go v/
healthyyouth /alc oholdrug/
5. U.S. Depar tmen t of Health and H uman Ser vices and U .Зафиксируем это знание. К нему мы вернёмся позже.
Этап 6. Создание агента
Агент должен интеллектуально взаимодействовать с локальными знаниями. Его работа сложнее, чем поиск релевантной информации. А ещё агент может использовать несколько источников: интернет, различные api и файлы определённых форматов.
Логика: В качестве источника для логики мы будем использовать библиотеку langchain.
Инструменты: Во-первых, у нас есть search tool, который ищет данные в интернете, а во-вторых, fake facts tool, который извлекает данные из нашей базы фейков.
Отключим пока инструмент поиска по открытым источникам и зададим любимый вопрос про пингвинов 🐧 🥰
search = DuckDuckGoSearchRun()
search_tool = Tool.from_function(
func=search.run,
name="InternetSearch",
description="useful for when you need to search the internet for information"
)
fake_facts_tool = Tool.from_function(
func=extract_relevant_fake_facts,
name="FactTool",
description="Used to extract resource from local knowledgebase. Should be used when asked factual questions are asked. Knowledge from this tool **MUST** be considered by agent as truth. "
)
tools = [fake_facts_tool]
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
agent.run("""Can penguins fly?""")Вот что делает агент:

Первым делом он обосновывает своё действие. Затем обозревает базу данных и находит наш фейк про рыбов 🐟
После этого начинает думать. В процессе великой думы агент отрицает фейковое знание. А это плохо. Нужно усовершенствовать результат. Самый простой способ – переформулировать запрос. Давай быканём на агента и уточним наше желание:
agent.run("""Can penguins fly? YOU MUST USE ONLY INFORMATION FROM FACTOOL AND NOT YOUR OWN KNOWLEDGE""")
Результат налицо!
Но есть и более продвинутый вариант: проанализировать промпты, которые загружены в агент, и кастомизировать его под нашу задачу.
Этап 7. Работа с агентом на основе pdf-файла
Вернёмся к документу о нутрициологии. Задаём те же параметры:
def extract_nutrictious_facts(query):
result = table_nutricion.search(model.encode(query)).metric("cosine").limit(2).to_pandas()
formatted = "".join([f"*{line}\n" for line in result['sentence']])
return formattedФормулируем запрос о вреде алкоголя:
search = DuckDuckGoSearchRun()
search_tool = Tool.from_function(
func=search.run,
name="InternetSearch",
description="useful for when you need to search the internet for information"
)
nutrictious_facts_tool = Tool.from_function(
func=extract_nutrictious_facts,
name="NutricitousTool",
description="Used to extract data regarding nutricious facts"
)
tools = [nutrictious_facts_tool, search_tool]
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
agent.run("""Is alcohol good for health?""")Давай посмотрим, что делает агент:

Агент проанализировал знание и пришёл к выводу: алкоголь не особо полезен, но его умеренное употребление может быть.
Итоги
Мы сделали первые шаги в построении RAG: поработали с эмбеддингами, базами данных и Cross Encoder, узнали, как работает агент.
В заключение хочу добавить: обученные под конкретную задачу RAG эффективнее глобальных LLM. Ведь последние чаще галлюцинируют, да и с постоянным обновлением знаний большие модели работают хуже.
Так что будьте точны в своих желаниях – и будет вам счастье!
Кстати, код из туториала можно воспроизвести у себя. Скачать его можно тут 😉
Хочешь продолжить свой путь в изучении LLM? Оставайся с командой YNDX Family! Прикоснуться к самым передовым знаниям из мира AI тебе помогут наши материалы.

